Understanding Metadata
Metadata is data about data(From Wikipedia). That is to say that metadata contains information about a piece of data. For example, if I own a car then I have a set of information about the car but which is not part of the car itself. Information such as the registration number, make, model, year of manufacture, insurance information, and so on. All of that information is collectively referred to as the metadata.
FileSystem
A file system is a way of organizing information/ data on any kind of storage device. In Linux and UNIX file systems metadata exists at multiple levels of organization. A good file system organizes data in an efficient manner and is tuned to the specific characteristics of the device.
File
A file is really just a block of logically related arbitrary data or bunch of bytes arranged in certain order(Contents of File). When Linux opens a file, it also creates a file object, which holds data about where the file is stored and what processes are using it. The file object (but not the file data itself) is thrown away when the file is closed.
Super block
The superblock is essentially file system metadata and defines the file system type, size, status, and information about other metadata structures (metadata of metadata). The superblock is very critical to the file system and therefore is stored in multiple redundant copies for each file system. The superblock is a very "high level" metadata structure for the file system. For example, if the superblock of a partition, /var, becomes corrupt then the file system in question (/var) cannot be mounted by the operating system. Commonly in this event fsck is run and will automatically select an alternate, backup copy of the superblock and attempt to recover the file system. The backup copies themselves are stored in block groups spread through the file system with the first stored at a 1 block offset from the start of the partition. This is important in the event that a manual recovery is necessary. You may view information about superblock backups with the command
iNode
An inode (short for "index node")exists in, or on, a file system and represents metadata about a file. For clarity, all objects in a Linux or UNIX system are files; actual files, directories, devices, and so on. There is one inode for each file (though with some filesystems, Linux has to create its own inodes because the information is spread around the filesystem). An inode contains essentially information about ownership (user, group), access mode (read, write, execute permissions), size of the file and file type. Each inode also contains a number unique to the filesystem partition; it's like a serial number for the file described by that inode.
Dentry
A dentry (short for "directory entry") is what the Linux kernel uses to keep track of the hierarchy of files in directories. A dentry is the glue that holds inodes and files together by relating inode numbers to file names. Each dentry maps an inode number to a file name and a parent directory. Dentries also play a role in directory caching which, ideally, keeps the most frequently used files on-hand for faster access. File system traversal is another aspect of the dentry as it maintains a relationship between directories and their files.
Disk Arrangement in UNIX
The boot block contains the code to bootstrap the OS. The super block contains information about the entire disk. The I-node list a list of inodes, and the data blocks contains the actual data in the form of directories and files.

The super block also contains an array to represent
free inodes. The size of this array need not be the actual number of
free inodes. During assignment of an inode to a new file, the kernel
searches the free inode list. If one free inode is found, that one is
returned. If the free inode list is empty, then it searches the inode
list for free inodes. Each inode will contain a type field, which if 0,
means the inode is free. It then fills the free inode list of super
block as much as it can, with number of free inodes from inode list. It
then returns one of these ones. It then remembers the highest inode
number. Next time it has to scan the inode list for free ones, it starts
from this remembered one. Hence it doesn't have to scan already scanned
ones. This improves the efficiency. While freeing an inode, if the free
list in super block has space enough, the freed one is put there. If
there is not enough space, and the freed inode number is less than the
remembered inode, then the remembered inode is updated with the freed
inode. If the freed inode number is greater than the remembered one,
then it doesn't have to update, because it will be scanned from the
remembered node and the freed one will be covered later.
The data blocks contain the actual data contained in the files or
directories. The data blocks are the physical blocks that is created in storage devices. In Unix, a directory is a special file. A directory file
contains names of the subdirectories and files present in that directory
and its corresponding inode number.
For better understanding check this:

Disk Allocation Methods(Data Blocks)
For more detailed explanation get into:
Metadata is data about data(From Wikipedia). That is to say that metadata contains information about a piece of data. For example, if I own a car then I have a set of information about the car but which is not part of the car itself. Information such as the registration number, make, model, year of manufacture, insurance information, and so on. All of that information is collectively referred to as the metadata.
FileSystem
A file system is a way of organizing information/ data on any kind of storage device. In Linux and UNIX file systems metadata exists at multiple levels of organization. A good file system organizes data in an efficient manner and is tuned to the specific characteristics of the device.
File
A file is really just a block of logically related arbitrary data or bunch of bytes arranged in certain order(Contents of File). When Linux opens a file, it also creates a file object, which holds data about where the file is stored and what processes are using it. The file object (but not the file data itself) is thrown away when the file is closed.
Super block
The superblock is essentially file system metadata and defines the file system type, size, status, and information about other metadata structures (metadata of metadata). The superblock is very critical to the file system and therefore is stored in multiple redundant copies for each file system. The superblock is a very "high level" metadata structure for the file system. For example, if the superblock of a partition, /var, becomes corrupt then the file system in question (/var) cannot be mounted by the operating system. Commonly in this event fsck is run and will automatically select an alternate, backup copy of the superblock and attempt to recover the file system. The backup copies themselves are stored in block groups spread through the file system with the first stored at a 1 block offset from the start of the partition. This is important in the event that a manual recovery is necessary. You may view information about superblock backups with the command
dumpe2fs /dev/foo | grep -i superblock which is useful in the event of a manual recovery attempt. Let us suppose that the dumpe2fs command outputs the line Backup superblock at 163840, Group descriptors at 163841-163841.
We can use this information, and additional knowledge about the file
system structure, to attempt to use this superblock backup: /sbin/fsck.ext3 -b 163840 -B 1024 /dev/foo. Please note that I have assumed a block size of 1024 bytes for this example.iNode
An inode (short for "index node")exists in, or on, a file system and represents metadata about a file. For clarity, all objects in a Linux or UNIX system are files; actual files, directories, devices, and so on. There is one inode for each file (though with some filesystems, Linux has to create its own inodes because the information is spread around the filesystem). An inode contains essentially information about ownership (user, group), access mode (read, write, execute permissions), size of the file and file type. Each inode also contains a number unique to the filesystem partition; it's like a serial number for the file described by that inode.
Dentry
A dentry (short for "directory entry") is what the Linux kernel uses to keep track of the hierarchy of files in directories. A dentry is the glue that holds inodes and files together by relating inode numbers to file names. Each dentry maps an inode number to a file name and a parent directory. Dentries also play a role in directory caching which, ideally, keeps the most frequently used files on-hand for faster access. File system traversal is another aspect of the dentry as it maintains a relationship between directories and their files.
Disk Arrangement in UNIX
The boot block contains the code to bootstrap the OS. The super block contains information about the entire disk. The I-node list a list of inodes, and the data blocks contains the actual data in the form of directories and files.

The super block contains the following information, to keep track of the entire file system.
Size of the file system
Number of free blocks on the system
A list of free blocks
Index to next free block on the list
Size of the inode list
Number of free the inodes
A list of free inodes
Index to next free inode on the list
Lock fields for free block and free inode lists
Flag to indicate modification of super block
Size of the file system represents the actual no of blocks (used + unused) present in the file system.
The super block contains an array of free disk block numbers,
one of which points to the next entry in the list. That entry in turn
will be a data block, which contains an array of some other free blocks
and a next pointer. When process requests for a block, it searches the
free block list returns the available disk block from the array of free
blocks in the super block. If the super block contains only one entry
which is a pointer to a data block, which contains a list of other free
blocks, all the entries from that block will be copied to the super
block free list and returns that block to the process. Freeing of a
block is reverse process of allocation. If the list of free blocks in
super block has enough space for the entry then, this block address will
be marked in the list. If the list is full, all the entries from the
super block will be copied to the freed block and mark an entry for this
block in the super block. Now the list in super block contains only
this entry.
Index indexes to the next free disk block in the free disk block list.
 | |
| Allocation Of Data Blocks |
During all these allocations, in a
multi-tasking environment, there is a chance of the inodes getting
corrupted. Like if one process was trying to allocate an inode and was
preempted by the scheduler, and a second process does the same for same
inode, it will be a critical problem. Hence lock flags are introduced.
While accessing inodes, that inode will be locked. One more flag to
indicate that the super block has been modified, is present in the super
block.
 |
| Assignment of New iNodes |
The I-node list (which server the purpose as FAT+ directory entries in DOS) is a list of inodes, which contains the following entries.
Owner
Type
Last modified time
Last accessed time
Last inode modified time
Access Permissions
No of links to the file
Size of the file
Data blocks owned
Owner indicates who owns the file(s) corresponding to this inode.
Type indicates whether inode represents a file, a
directory, a FIFO, a character device or a block device. If the type
value is 0 then the inode is free.
The times represent when, the file has been modified,
when it was last accessed, or when the inode has been modified last.
Whenever the contents of the file is changed, the "inode modified time"
also changes. Moreover it changes when there are changes for the inode
like permission change, creating a link etc.
Each file will be having nine access permissions for
read, write and execute, for the owner, group and others in rwx rwx rwx
format.
In Unix we can create links to some files or
dThe data blocks contain the actual data contained in the files or
directories. In Unix, a directory is a special file. A directory file
contains names of the subdirectories and files present in that directory
and its corresponding inode number.irectories. So we need to have a count of how many links are pointing
to the same inode, so that if we delete one of the links the actual data
is not gone.
Size of the file represents the actual size of the file.
In Unix, we have a kind of
indexing to access the actual data blocks that contains data. We have an
array of which (in each inode) first ten elements indicate direct
indexing. The next entry is single indirect, then comes double indirect
and then triple indirect. By direct indexing we mean that, the value in
the array represents the actual data block. If the file needs more than
10 blocks, it uses single indirect indexing, means this is an index to
the a block which contains an array of disk block numbers which in turn
represent the actual disk block. If all these are exhausted, then double
indirect indexing is used and then triple indirect.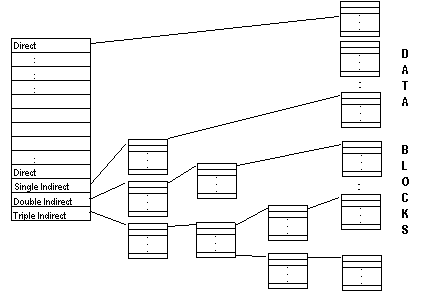 |
| iNode DataBlock Representation |
For better understanding check this:

Disk Allocation Methods(Data Blocks)
- model the physical disk addresses with block numbers (usually each block number corresponds to one sector id, but sometimes a block corresponds to multiple sector ids)
- I/O layer of the OS translates disk addresses, expressed as a combination of a drive #, a cyclinder #, a track #, and a sector #, into sector ids (and if necessary block numbers).
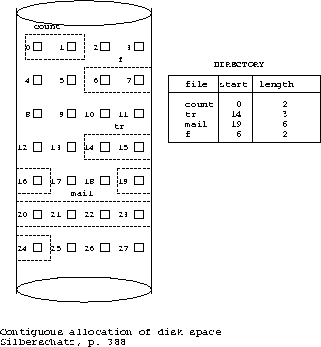
- a)contiguous allocation
- each file occupies a set of consecutive addresses on disk
- each directory entry contains:
- file name
- starting address of the first block
- block address = sector id (e.g., block = 4K)
- length in blocks
- usual dynamic storage allocation problem
- use first fit, best fit, or worst fit algorithms to manage storage
- if the file can increase in size, either
- leave no extra space, and copy the file elsewhere if it expands
- leave extra space
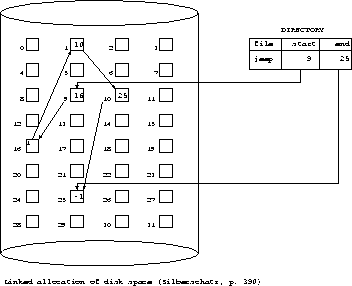
- b)linked allocation
- each data block contains the block address of the next block in the file
- each directory entry contains:
- file name
- block address: pointer to the first block
- sometimes, also have a pointer to the last block (adding to the end of the file is much faster using this pointer)
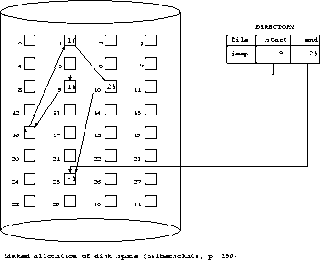
- a view of the linked list
- c)indexed allocation
- store all pointers together in an index table
- the index table is stored in several index blocks
- assume index table has been loaded into main memory
- i)all files in one index


The index has one entry for each block on disk.
- better than linked allocation if we want to seek a particular offset of a file because many links are stored together instead of each one in a separate block
- SGG call this organization a ``linked'' scheme, but I call it an ``indexed'' scheme because an index is kept in main memory.
- problem: index is too large to fit in main memory for large disks
- FAT may get really large and we may need to store FAT on disk, which will increase access time
- e.g., 500 Mb disk with 1 Kb blocks = 4 bytes * 500 K = 2Mb entries
- ii)separate index for each file
- index block gives pointers to data blocks which can be scattered
- direct access (computed offset)
- a)one index block per file (assumes index is contiguous)

- b)linked list of index blocks for each file
- c)multilevel index
- d)combined scheme (i-node scheme) used in UNIX
- store all pointers together in an index table


For more detailed explanation get into:
The Design of the Unix Operating System By Maurice J. Bach
No comments:
Post a Comment